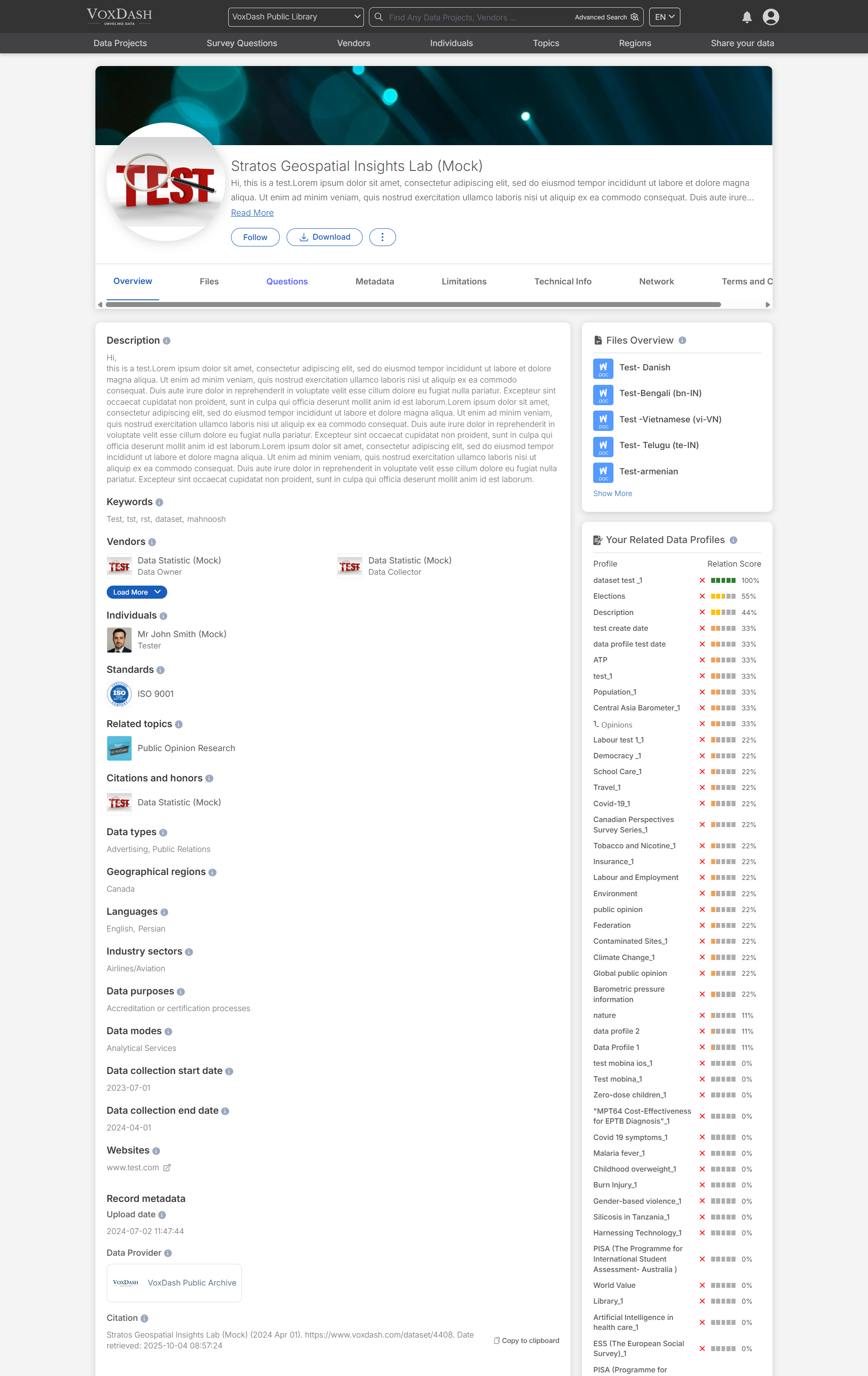
Overview Section
The Overview page provides a comprehensive summary of the data project. This includes key details such as:- Description: Provides a detailed summary of the dataset, including its scope, content, and context. This section helps users quickly understand what the data covers, how it was collected, and its potential uses, without having to examine the full files.
- Keywords: Provides a list of descriptive terms or phrases associated with the dataset. These keywords enhance searchability, enabling users to locate datasets even if they don’t know the exact title or topic categorization.
- Collection Date: The date when the data was collected.
- Vendors and Contributors: Individuals and organizations involved in data collection.
- Standards: Indicates formal certifications, quality benchmarks, or methodological standards applied to the dataset. Examples include ISO certifications, industry-specific compliance standards, or recognized research protocols helping users evaluate methodological rigor and compatibility with other datasets.
- Related topics: Shows the thematic areas or research domains relevant to the dataset. Topics are used for discovery and categorization, making it easier to find datasets covering similar subjects or related questions.
- Citations and honors: Lists academic citations, institutional references, or honors connected to this dataset. These entries show where the dataset has been referenced, recognized, or awarded by universities, research centers, or other organizations. They highlight the dataset’s impact and credibility within the research and policy community.
- Data types: Specifies the general form of the dataset’s content such as numerical measurements, categorical variables, text responses, geospatial coordinates, or coded qualitative data. Helps users assess whether the dataset structure fits their intended analysis.
- Geographical Regions: The regions covered by the data project.
- Resource Websites: Links to external resources related to the project.
- Languages: Indicates the languages in which the dataset’s content is recorded or in which data collection was conducted. This can help assess respondent language context or the need for translation before analysis.
- Industry sectors: Shows which economic or occupational sectors the dataset relates to, based on standard industry classifications. Useful for domain-specific research, policy analysis, or business intelligence.
- Data purposes: Describes the original or permitted uses of the dataset such as research, business intelligence, advocacy, or AI training. Understanding the stated purpose helps assess whether the data is suitable and legally appropriate for your intended use.
- Data modes: Describes the method(s) used to gather the data e.g., Computer-Assisted Telephone Interviewing (CATI), face-to-face interviews, online surveys, or automated collection. Understanding the mode is important for evaluating methodology and potential biases.
- Data collection start date: The exact date and time when fieldwork or data gathering began. This helps situate the dataset in a temporal context, especially for time-sensitive research.
- Data collection end date: The exact date and time when fieldwork or data gathering was completed. Combined with the start date, it indicates the total duration of data collection, which can impact sample quality and comparability.
Files Section
The Files lets you view and download all available files related to the data project. File types may include raw data, reports, and supplementary documentation.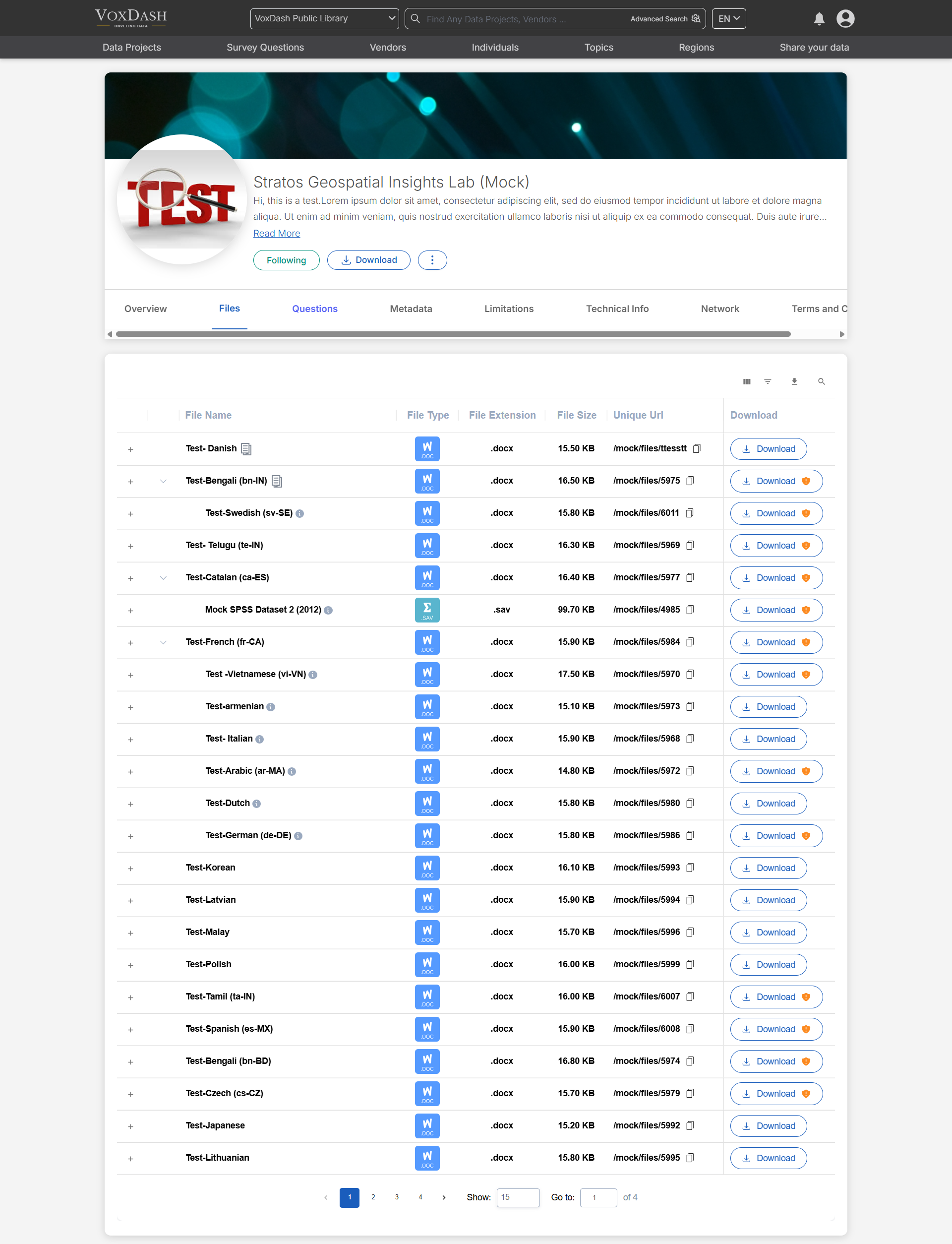
Questions Section
In the Questions section, you can explore all the survey questions associated with the data project. This section includes filtering options similar to those found in the Survey Questions section, enabling you to search and categorize questions efficiently.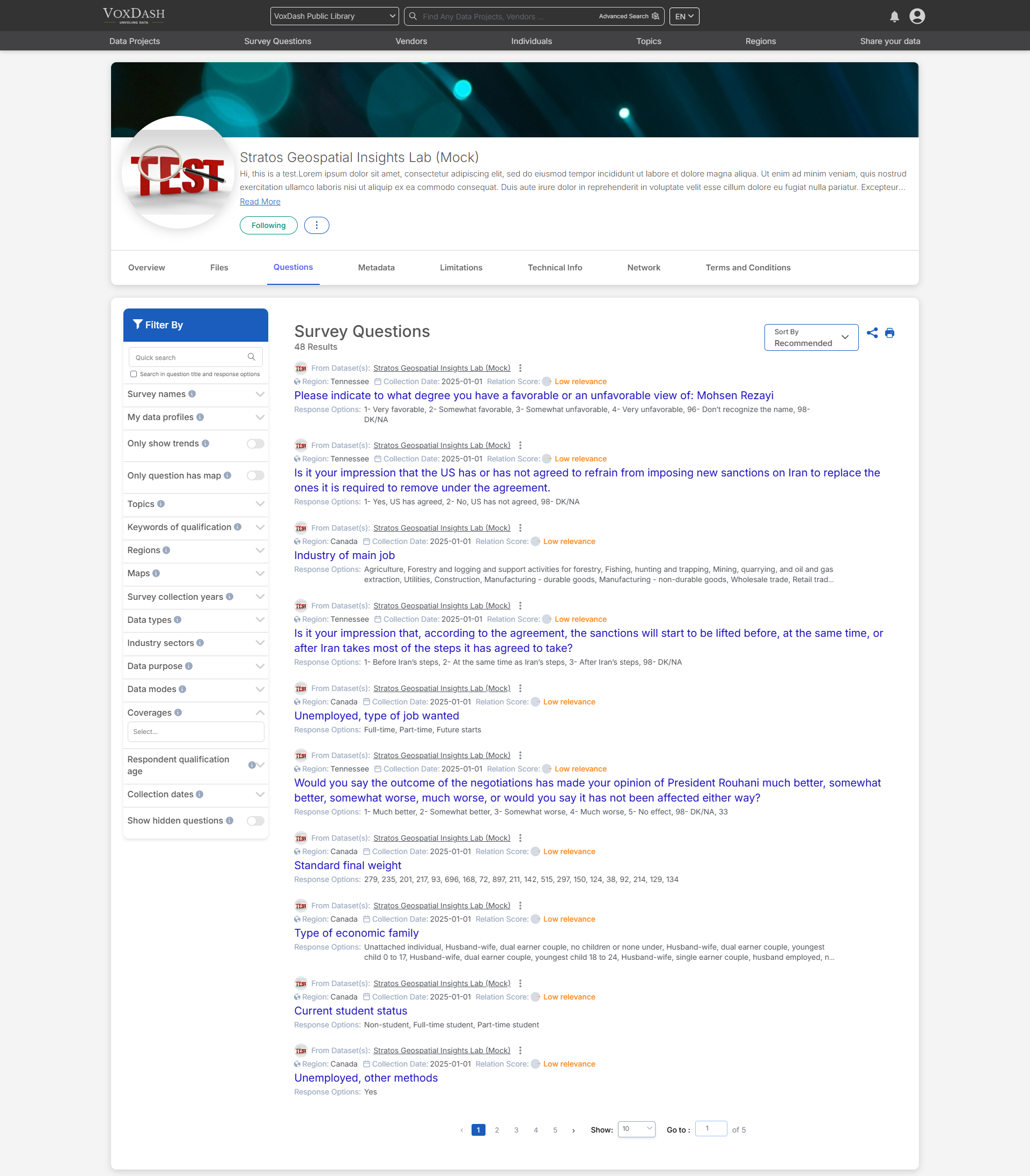
Metadata Section
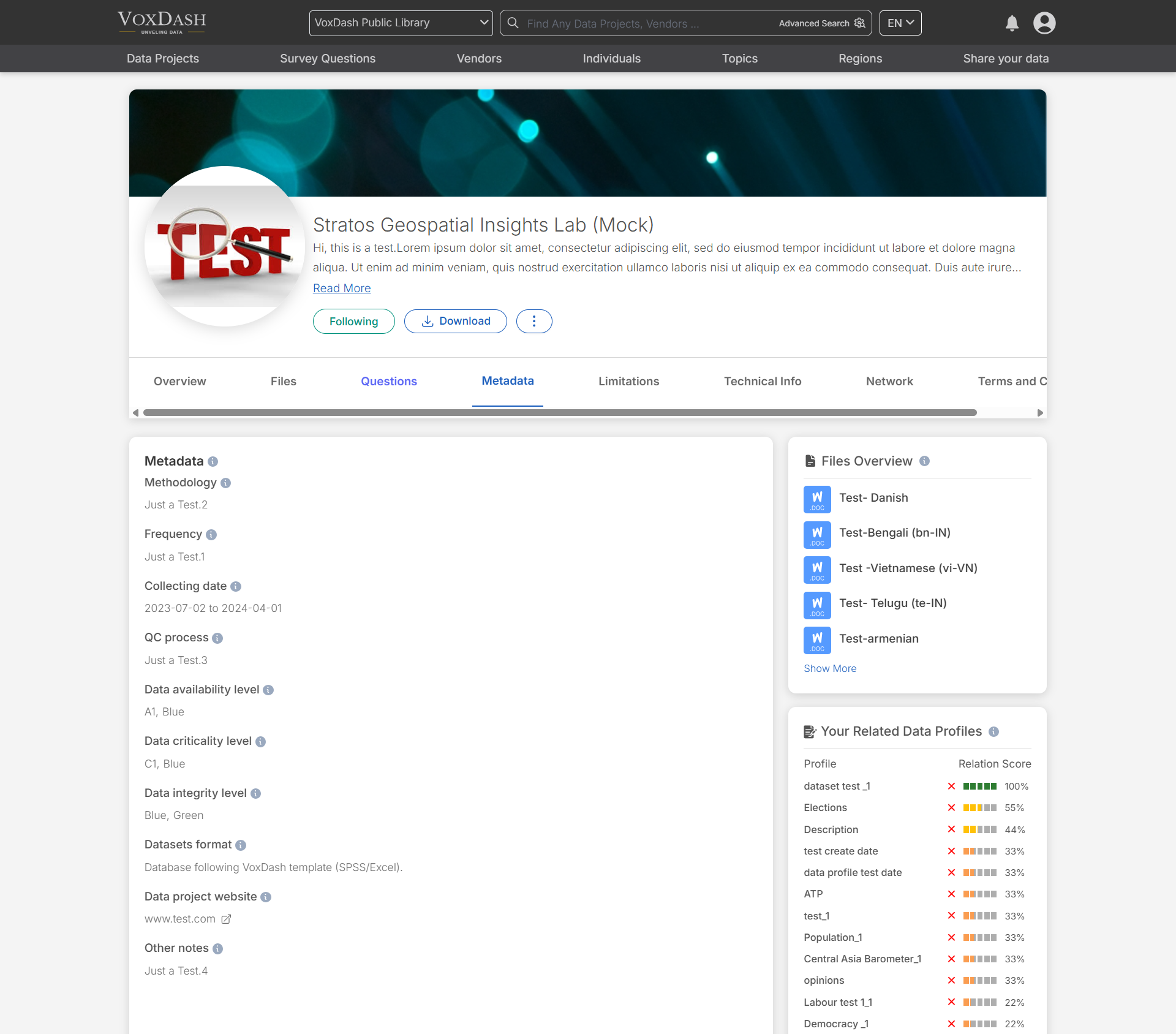
The Metadata section provides essential information such as:- Methodology: A description of the research design, sampling strategy, instruments, and procedures used to collect the data. This helps users evaluate the quality and comparability of the dataset.
- Frequency: Indicates how often data was collected (e.g., one-time, monthly, annually, or rolling basis).
- Collecting date: The full time span during which data was gathered for this dataset. It may include continuous or intermittent collection within this period.
- QC process: Details about the quality control procedures applied during or after data collection, such as verification, cleaning, and validation steps.
- Data availability level: Indicates how reliably and quickly this dataset can be accessed whether it’s real-time, scheduled, on-demand, archived, or subject to downtime. Helps you understand availability expectations, access constraints, and potential delays.
- Data criticality level: Indicates how essential this dataset is to its original context such as operations, compliance, safety, or decision-making. Higher criticality suggests the data plays a vital role and may require greater care, accuracy, and reliability in use.
- Data integrity level: Describes the trustworthiness and quality of the dataset such as whether it has been verified, audited, complete, tamper-evident, or reconciled. These indicators help assess whether the data can be reliably used for analysis, reporting, or decision-making.
- Datasets format: Displays the file format of the uploaded dataset (e.g., CSV, JSON, Excel, Parquet). The format determines how the system reads and interprets the data, including parsing rules, supported data types, and compatibility with analysis features. Knowing the format helps you understand potential limitations (such as schema handling, column types, or compression) and ensures correct processing within the platform.
- Data project website: Displays the file format of the uploaded dataset (e.g., CSV, JSON, Excel, Parquet). The format determines how the system reads and interprets the data, including parsing rules, supported data types, and compatibility with analysis features. Knowing the format helps you understand potential limitations (such as schema handling, column types, or compression) and ensures correct processing within the platform.
- Other notes: Any additional remarks, clarifications, or context provided by the data provider that don’t fit into the other metadata fields.
- Collection Date: When the data was gathered.
- Data Project Website: A link to the project’s official website for further details.
Limitations Section
Any constraints or restrictions related to the data project are listed in the Limitations page. This may include data accuracy, coverage gaps, or methodological limitations.- Limitation on geographies: Specifies the countries, territories, or geographies where the dataset may or may not be used, due to licensing, privacy laws, or contractual agreements.
- Limitation on industry sectors: Indicates economic or occupational sectors where use of the dataset is restricted or prohibited.
- Limitation on data purpose: Lists the purposes for which the dataset may not be used, such as certain types of research, analytics, or operational work.
- Limitation on sub-license: States whether the dataset can be re-licensed or sublicensed to third parties, and under what conditions.
- Data license: Indicates the legal terms for using, sharing, or modifying this dataset. Some licenses allow unrestricted reuse, while others limit commercial use, require attribution, or prohibit changes. Always review the license before using the data.
- Data regulations: Indicates which privacy laws or regulatory frameworks govern this dataset such as GDPR, HIPAA, or CCPA. These rules may affect how you can access, use, share, or analyze the data, especially for sensitive or personal information.
- Data elements: Shows the types of information contained in the dataset such as personal identifiers, health data, financial records, or public-use content. Knowing which elements are included helps assess privacy risks, legal restrictions, and potential for analysis.
- Data confidentiality level: Indicates how sensitive or restricted the dataset is ranging from public and anonymized data to classified or legally protected information. These levels help determine what precautions or permissions are required for access or use.
- Restriction: Describes any additional specific restrictions on the dataset not already covered by other limitation fields.
- Citation requirement: States if and how the dataset must be cited when used in publications or outputs.
- Disclaimer: Provides statements from the data provider clarifying liability, accuracy, or interpretation of the dataset.
- URLs related to limitations: Links to online resources with more detail about the dataset’s usage restrictions.
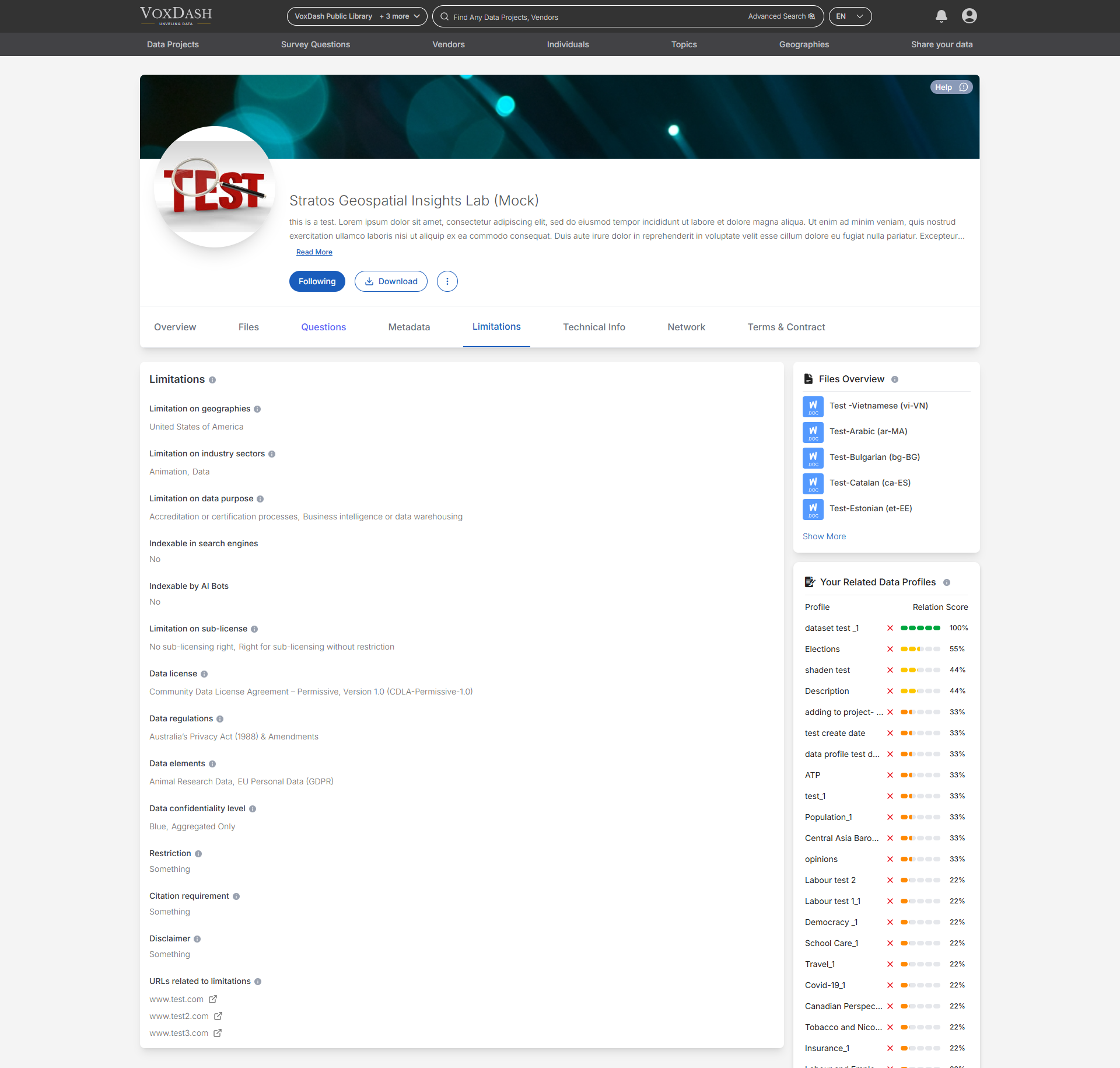
Technical Section
The Technical Info section displays data you added via the survey data entry page. This includes key statistical details such as:- Margin of Error: The possible deviation in survey results.
- Respondent Demographics: Information about the age groups of participants.
- General Population Insights: Broader demographic data for context.
- Sampling method: Describes how participants were selected whether through random sampling, quotas, referrals, or self-selection. This affects how representative the data is and what kinds of statistical inferences are valid. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Is the survey sampling probabilistic?: Indicates whether participants were selected using probability sampling methods, where every individual had a known, non-zero chance of selection. Probabilistic samples are essential for generalizing to the broader population. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Sampling frame: Indicates how participants were reached e.g., through phone, mail, online panels, or administrative records. This affects who was included or excluded, and should be considered when assessing coverage, representativeness, and potential bias in the dataset.
- Sampling frame source: Identifies the source of the sampling frame (e.g., list-based, RDD, ABS, panel provider). This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Coverage: Describes the geographic or administrative scope of the dataset such as neighborhood, city, national, or global. Helps you understand how localized or broad the data is, and whether it aligns with your area of interest.
- Call-center physical location: Call-Center physical location
- Standard disposition code source: Indicates the source or reference used for assigning standard disposition codes (e.g., AAPOR, ISO). This helps ensure consistent classification of respondent outcomes.
- Version of the standard: Specifies the version of the standard disposition code framework used. This is important for transparency and compatibility when comparing datasets across time or sources.
- Frame: Describes the sampling frame used to select respondents (e.g., address-based, telephone-based, panel). The frame defines the population that the survey aims to represent.
- Survey outcome rates: Provides key survey outcome metrics such as response rate, cooperation rate, and refusal rate. These metrics help assess data quality and representativeness.
- Sampling procedures: Details the sampling procedure used (e.g., stratified random sampling, quota sampling, RDD). This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Within household method: Indicates whether within-household respondent selection methods were used (e.g., Kish grid, last birthday).
- Respondent qualification age: The age range used to qualify respondents for this survey. If unspecified, no age-based restriction was applied to participant eligibility. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Respondents qualification criteria (screeners imposed): Describes the criteria used to qualify respondents for inclusion in the sample (e.g., age, occupation, behavior).
- Incidence rate (IR%): The percentage of contacted individuals who qualified for and completed the survey. This value is calculated by the data provider’s own system and displayed by VoxDash as submitted. VoxDash does not recalculate or verify it.
- Quotas imposed: States whether quotas were used and what dimensions they were based on (e.g., age, gender, region). This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Oversamples: Identifies whether oversamples were used for specific populations and explains their rationale. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Boost or augment: Specifies whether any subgroup was oversampled or augmented beyond the general sampling plan.
- Survey invitation and respondent recruitment procedure: Explains how respondents were invited to participate in the survey (e.g., email, phone call, in-person). This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Average length of interview (LOI): The average duration, in minutes, it took respondents to complete the interview.
- Was the respondent in any way incentivized?: Indicates whether respondents received incentives and what type (e.g., cash, gift card). This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Any occurrences that might have influenced sampling procedures or respondent participation and/or answers: Number of times the survey was administered (e.g., single wave vs. repeated cross-section). This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Sample size reported by source: The number of completed responses or cases as stated by the original data provider. This reflects what the source organization has declared as their achieved sample size. This value is calculated by the data provider’s own system and displayed by VoxDash as submitted. VoxDash does not recalculate or verify it.
- Sample size calculated by VoxDash: The number of valid cases recognized by VoxDash after processing the uploaded dataset. This figure may differ from the reported size if records are missing, incomplete, or filtered out during validation.
- Population size: Estimated total size of the population from which the sample was drawn. This value is calculated by the data provider’s own system and displayed by VoxDash as submitted. VoxDash does not recalculate or verify it. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- Sampling margin of error calculated by VoxDash: This Margin of Error is estimated by VoxDash using standard probabilistic assumptions. It reflects expected sampling variability under ideal conditions, assuming a simple random sample. This assumption is based on the data provider’s claim that the sample is probabilistic. The estimate does not account for design effects or real-world sampling imperfections. In this formula, p is the population proportion (typically 0.5 to yield the most conservative estimate), n is the sample size (calculated by VoxDash from the dataset), and N is the population size.
- Credibility interval: The number of percentage points on either side of a survey estimate that captures uncertainty. This value is calculated by the data provider’s own system and displayed by VoxDash as submitted. VoxDash does not recalculate or verify it.
- Design effect: The reported design effect, which reflects the impact of the sample design on the standard error.
- Weighted: Indicates whether the data is weighted and, if so, the weighting methodology applied. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
- % called-back for QC: Percentage of interviews that were reviewed or recontacted for quality control purposes. This value is provided by the data provider. VoxDash displays it as submitted and does not modify or verify it.
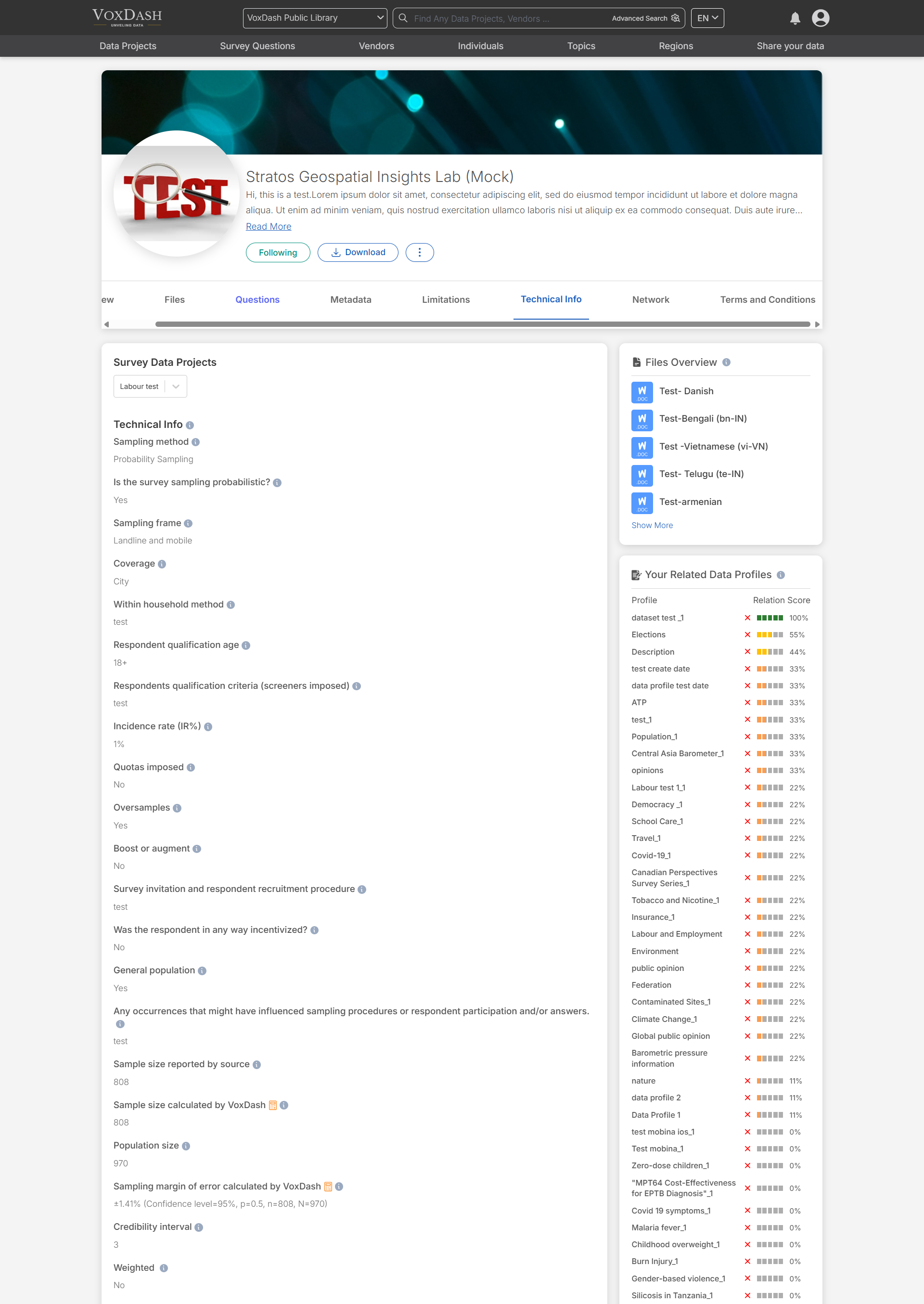
Network Section
The Network section showcases related data projects and dataset connections. This includes:- Related Data Projects: Other projects that share similarities.
- Dataset Network: Common vendors, contributors, and interrelated project insights.
Contracts Section
The Terms and Conditions section contains the terms and conditions governing the use of the data project. Be sure to review this section before utilizing the data.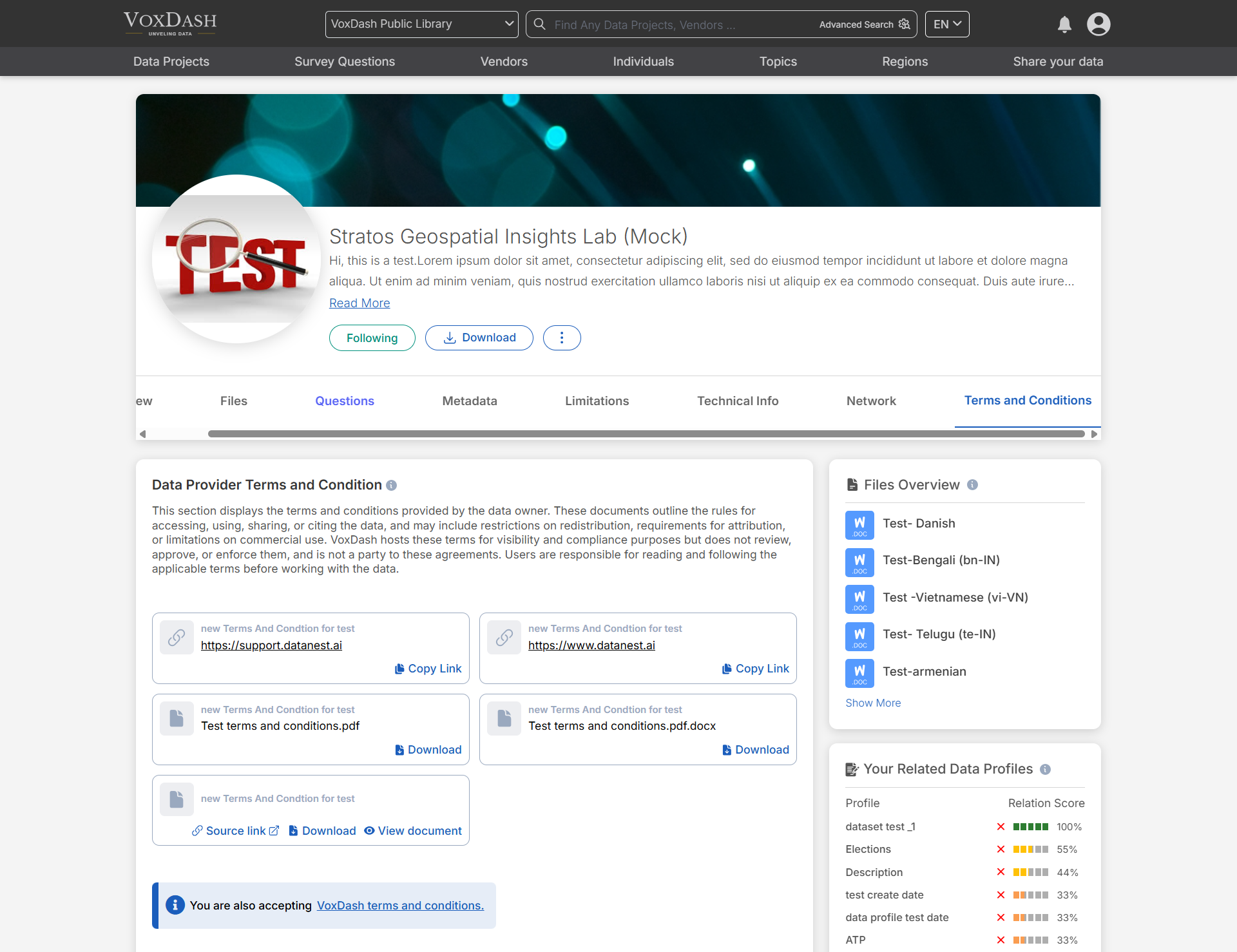
Claim, Report, or Improve a Dataset
The Claim, Report, or Improve Dataset feature allows users to contribute to dataset accuracy, ownership verification, and overall data quality. This helps maintain a trusted and reliable data environment across the platform.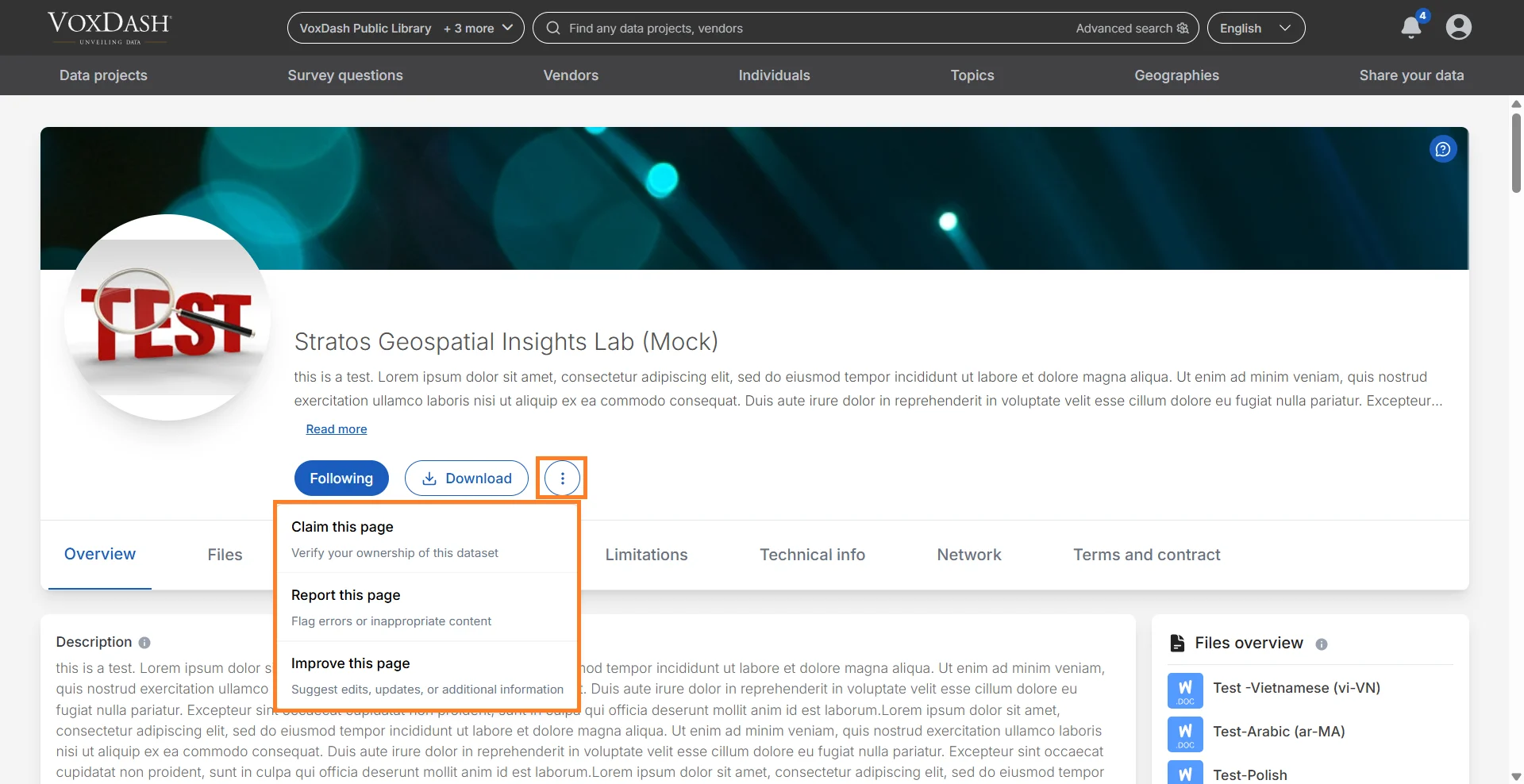
Report or Improve a Dataset
Users can report issues or suggest improvements for any dataset by submitting additional information directly from the dataset page. This feature is designed to help maintain accurate, complete, and up-to-date dataset records. Users may provide:- Corrections to dataset information
- Updated descriptions or metadata
- Missing details such as categories, tags, or ownership information
- Feedback regarding data quality or accuracy
- Requests to update outdated content
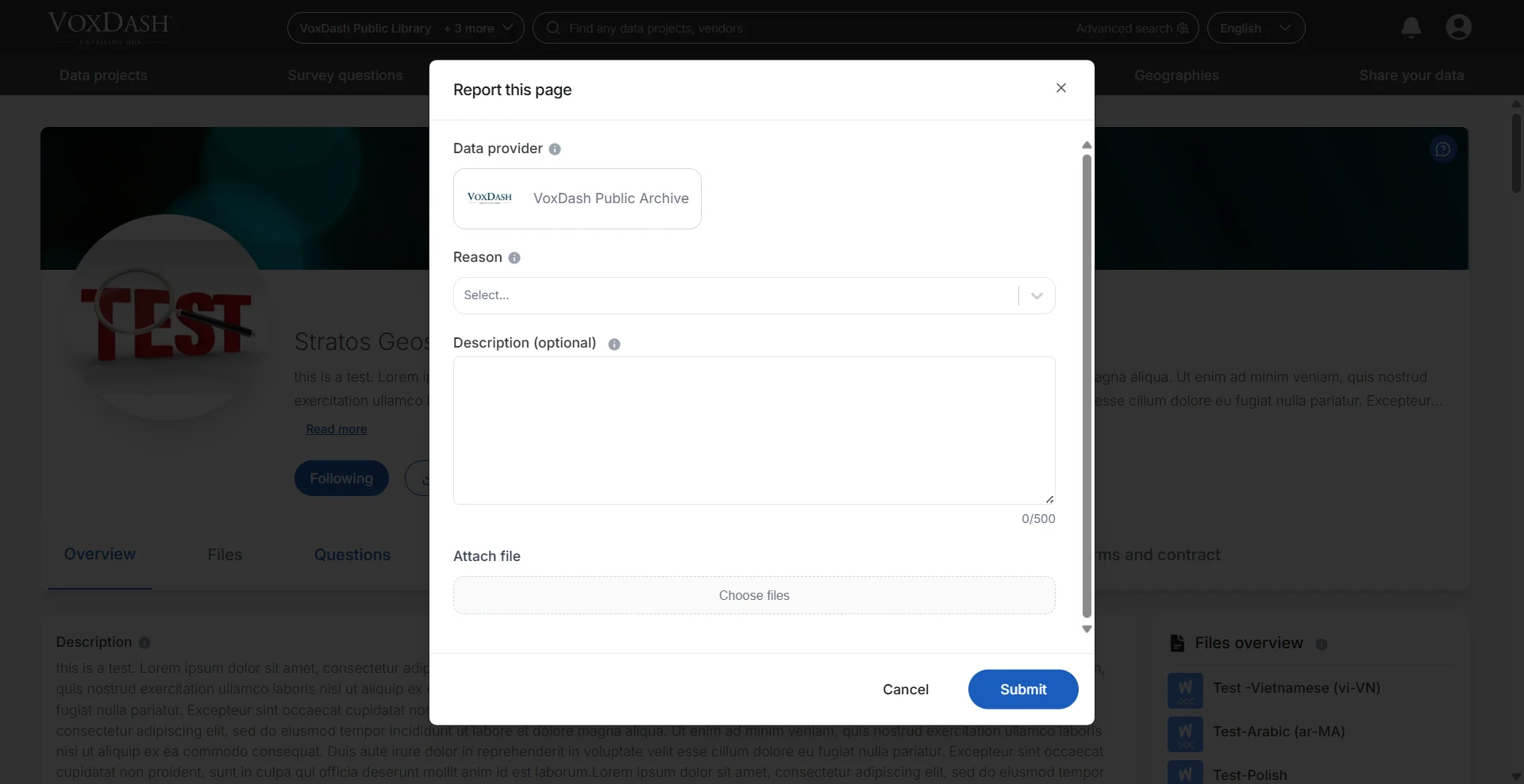
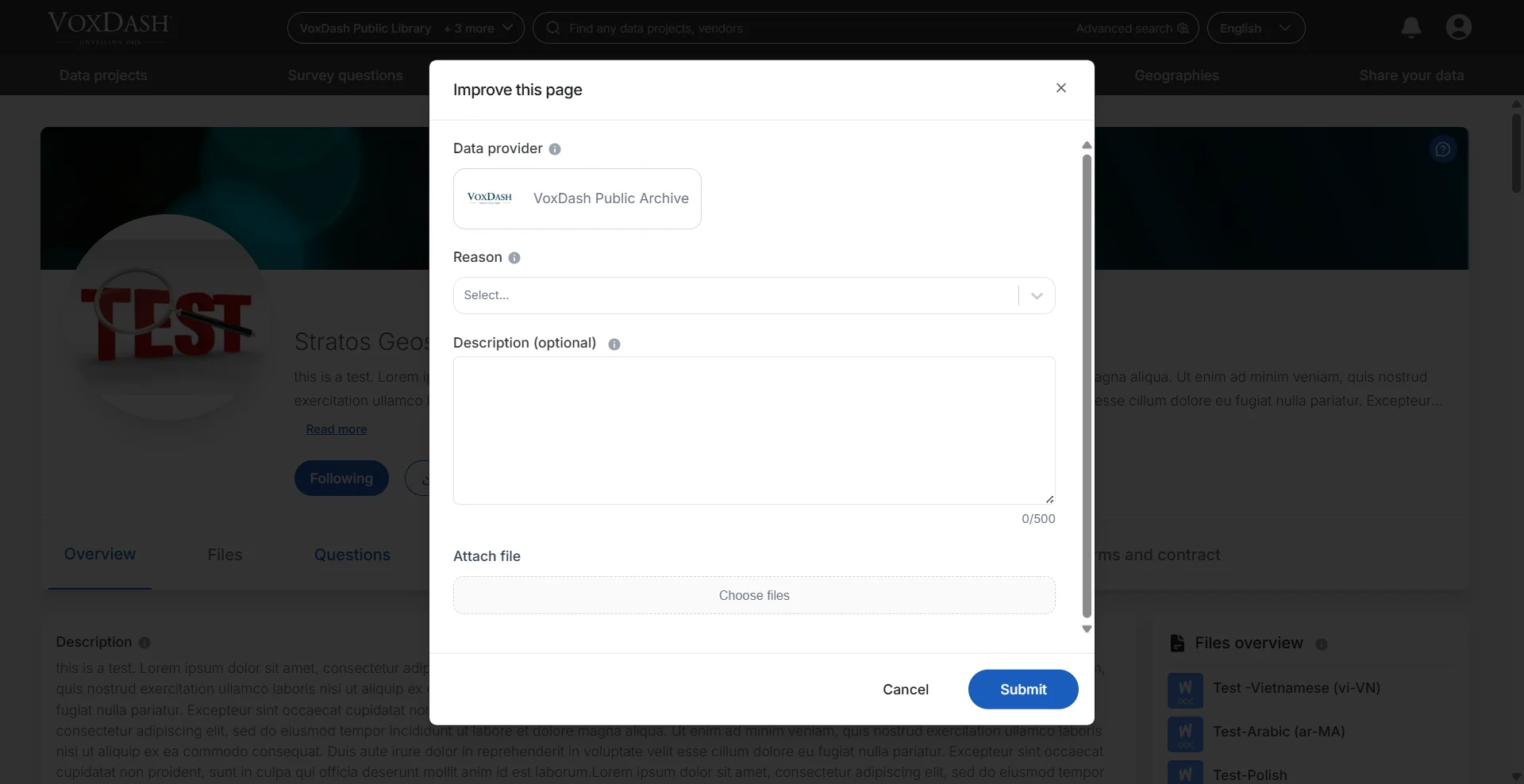
- Open the dataset page.
- Select Report or Improve Dataset.
- Enter the requested information and supporting details.
- Submit the request for review.
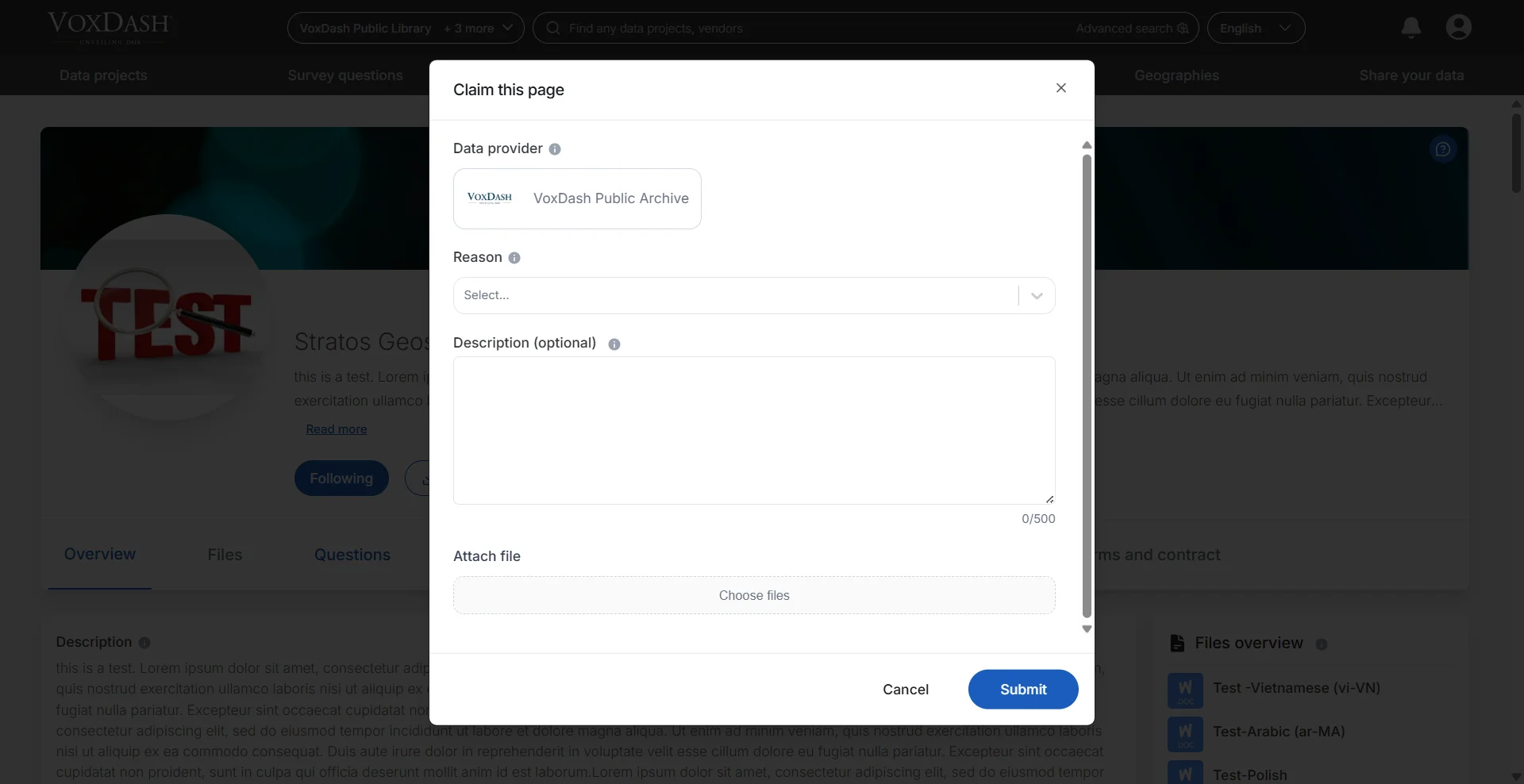
Claim a Dataset
Dataset co-owners can claim ownership of a dataset to verify and manage its public availability and information. When a dataset is claimed:- Public access to the dataset is temporarily paused.
- The dataset enters a verification and approval process.
- All registered co-owners and platform administrators must review and confirm the claim.
- The dataset will become publicly accessible again only after approval is completed.
Important Notes
- Only authorized co-owners can claim a dataset.
- Claims and improvement requests may require administrator approval.
- During the claim verification process, some dataset features or visibility settings may be temporarily restricted.
- Users will receive notifications regarding the status of their submitted claims or improvement requests.